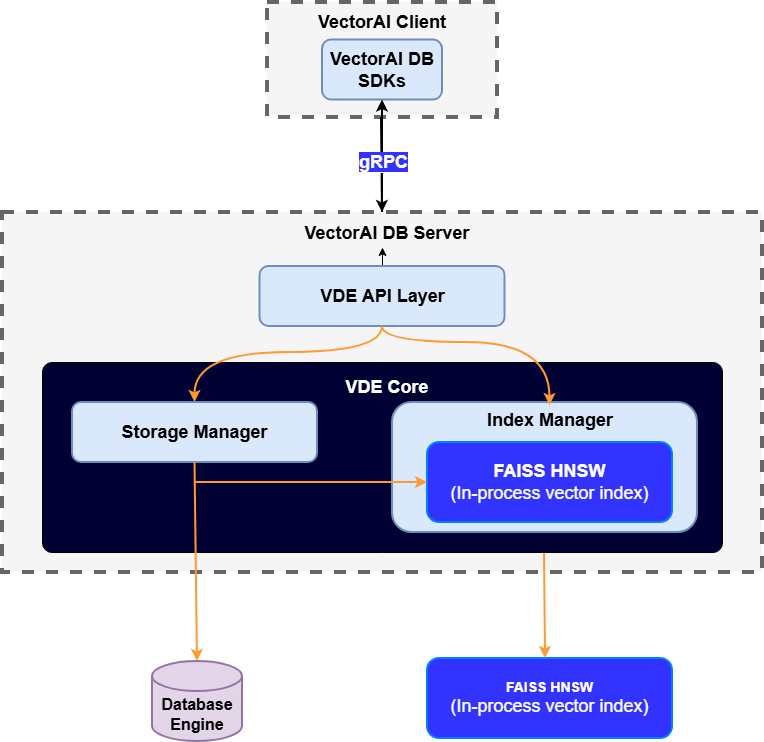
Architecture components
1
VectorAI DB SDKs
Client libraries (such as Python) communicate with the VectorAI DB server via gRPC to create collections, insert vectors, and run similarity searches. The SDK abstracts the complexity of gRPC communication.
2
Vector Data Engine (VDE) API layer
Receives gRPC requests from SDKs, validates and processes them, then routes them to the appropriate internal components in the VDE core. This layer serves as the gateway between client applications and the vector processing engine.
3
Storage manager
Handles persistent storage and retrieval of vectors and metadata while coordinating with the underlying database engine for durability and consistency. This component ensures data integrity across all vector operations.
4
Index manager
Manages vector indexes by building, updating, and querying them for efficient similarity search. The index manager coordinates with ANN algorithms to optimize search performance.
5
Approximate nearest neighbor (ANN)
Uses an in-process vector index for fast similarity search over high-dimensional embeddings. This component trades exact precision for speed.
6
Database engine
Stores vector data, metadata, and collection information durably on disk.